Restriktioner
Tabeller brukar ha restriktioner för att skapa en logisk stabilitet. En restriktion på en tabell som vi redan stött på är tabellens primary key. En primary key måste ha ett unikt värde och det värdet får inte vara NULL. När vi skapar en tabell kan vi välja att sätta restriktioner på attribut för att göra tabellen säkrare från logiska fel (dock är det inget vi måste). Här är några restriktioner vi kan sätta på attributen:
PRIMARY KEY: Attributet är en primary key, det måste vara unikt och får inte varaNULL.NOT NULL: Attributet får inte varaNULL, det måste vara tilldelat ett värde.UNIQUE: Attributet måste vara unikt.CHECK(): Lägg till ett eget villkor som måste resultera i sant ellerUNKNOWN.
Restriktioner kan även namnges. Detta gör man genom att skriva CONSTRAINT <name> CHECK(), där <name> är ett valfritt namn. Att ge en restriktion ett namn låter oss att referera till den restriktionen så att vi kan ändra eller ta bort den vid ett senare tillfälle.
Auto-genererade ID
Ofta när man skapar en tabell så brukar man använda ett ID som PRIMARY KEY. Detta är för att det är enkelt att generera unika heltal och för att heltal är snabba att jämföra, vilket resulterar i bra prestanda. Vi kan säga åt SQL att ett generera tal åt oss genom att skriva GENERATED ALWAYS AS IDENTITY efter ett attribut. Mer konkret exempel finns nedan.
I tidigare versioner av Postgres brukade man skriva SERIAL istället. Detta var deras egna variant av ett auto-genererat nummer. Vi kommer inte använda oss av det, men det kan vara bra att veta om.
Skapa en tabell
Nu bör vi kunna köra vårat första SQL-kommando och skapa en tabell. Se till att först starta psql (psql (SQL Shell) på Mac eller runpsql.bat på Windows) och ansluta dig till databasen tweeter med användaren tweeter_admin (eller vad ni nu valde för namn).
Tabellen vi vill skapa först är users(user_id, username, email, age) som ska innehålla information om våra användare. Innan vi skapar tabellen måste vi logiskt tänka igenom alla attributs datatyper och restriktioner.
user_idvill vi ska vara det tal som identifierar en användare, alltså ett unikt heltal (INTEGER) som inte får varaNULL. Då det ska användas som ett id-nummer så bör det ha restriktionenPRIMARY KEY. Dock vill vi inte själva sätta in värden, utan vi vill att ID ska genereras automatiskt. Därför kan vi då använda oss avGENERATED ALWAYS AS IDENTITY.usernamevill vi ska vara en sträng av karaktärer som är användarens visningsnamn. Olika användare kommer säkert vilja ha olika längd på sitt användarnamn, så vi bör användaTEXT. Vi vill också att alla användare ska ha ett användarnamn (det får inte varaNULL). Så attributet bör ha restriktionenNOT NULL. Om vi vill kan vi sätta in enCHECKför att se till att användarnamnet är mellan en viss längd med hjälp av funktionenLENGTH.emailär också en varierande sträng av karaktärer, alltsåTEXT. Eftersom vi vill att användarna anger en unik email address kommer vi sätta restriktionenUNIQUE. Vi vill även att användarna anger sin email address, alltså att den ärNOT NULL. Vi kan använda flera restriktioner genom att skriva dem efter varandra, d.v.s.UNIQUE NOT NULL(ordningen spelar ingen roll, såNOT NULL UNIQUEskulle fungera lika bra). Eftersom restriktionen ärUNIQUE NOT NULLså skulle vi kunna använda attributet som enPRIMARY KEY. Vi valde att ha ett id-nummer istället då en användare kanske vill ändra sin mail i framtiden. Även om det går att ändra värdet på enPRIMARY KEY, så är det bäst praxis att inte göra det, för prestanda och stabilitet. Vi kan även se till att emailen är på korrekt format genom att lägga till vårat egna villkorCHECK(email LIKE '%@%.%').ageär ett heltal, d.v.s.INTEGER. Dock vill vi att de användare som anger sin ålder inte anger ett negativ värde eller ett för stort värde. Vi vill lägga tillCHECK(age BETWEEN 0 AND 150). Om ni inte tycker det är logiskt att en ettåring kan vara med i ert system får ni naturligtvis sätta en högre gräns (och kanske en lägre övre gräns?).
| Name | Datatyp | Restriktioner |
|---|---|---|
user_id | INTEGER | PRIMARY KEY GENERATED ALWAYS AS IDENTITY |
username | TEXT | NOT NULL CHECK(LENGTH(username) BETWEEN 4 AND 32) |
email | TEXT | UNIQUE NOT NULL CHECK(email LIKE '%@%.%') |
age | INTEGER | CHECK(age BETWEEN 0 AND 150) |
Syntaxen för att skapa en tabell är:
CREATE TABLE <name> (
<attribute_name> <datatype> <optional_constraints>,
...
);<name>är tabellens namn.<attribute_name>är attributets namn.<data_type>är attributets datatyp.<optional_constraints>är valfria restriktioner vi vill sätta på attributet.
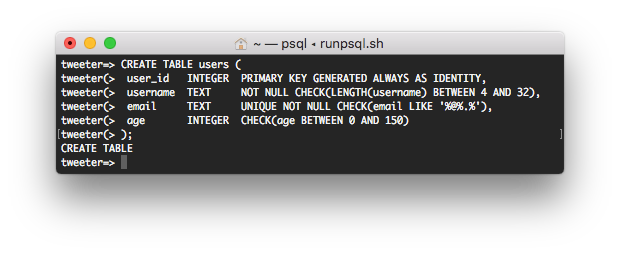
I vårat fall ser koden för att skapa tabellen users ut så här:
CREATE TABLE users (
user_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
username TEXT NOT NULL CHECK(LENGTH(username) BETWEEN 4 AND 32),
email TEXT UNIQUE NOT NULL CHECK(email LIKE '%@%.%'),
age INTEGER CHECK(age BETWEEN 0 AND 150)
);
Mellan parenteserna listar vi alltså upp alla attribut och separerar dem med kommatecken. Viktigt! Det sista attributet ska inte ha ett kommatecken efter sig, då det kommer resultera i ett felaktigt syntax. Kom även ihåg att whitespace inte spelar någon roll. Du kan ha hur många mellanslag du vill eller skriva allt på en enda lång rad.
Koden kommer köras när det stöter på ett semikolon följt av ett enterslag. Om allt går som det ska kommer texten "CREATE TABLE" upp. Om det inte går som det ska... Dår är du körd (eller så skriver du en kommentar här på ludu med ditt felmeddelande/problem så löser vi det).
En till tabell
Att ha en databas med bara en tabell av användare är inte så kul. Nu vill vi skapa en till tabell som innehåller alla tweets! De attribut som vi vill förknippa med en tweet kan då vara användaren som postat tweeten, innehållet i tweeten och tiden som den postades. Inget av dessa attribut kan vara en primary key då inget är unikt för ett tweet. Vi kommer alltså använda oss av ett ID-nummer igen. Tabellen vi vill skapa är då tweets(tweet_id, poster_id, content, time_posted).
I detta fall vill vi dessutom att poster_id i tabellen ska vara en existerande användare, alltså ett ID som finns i tabellen users. För att se till att detta alltid stämmer måste vi sätta en ny restriktion på attributet.
Foreign keys
Det vi behöver göra för att referera till ett attribut är att skriva REFERENCES följt av tabellens namn och namnet på attributet vi vill referera till. Här är ett exempel hur vår tweets tabell skulle kunna se ut:
CREATE TABLE tweets (
tweet_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
poster_id INTEGER REFERENCES users(user_id),
content TEXT NOT NULL CHECK(LENGTH(content) BETWEEN 4 AND 144),
time_posted TIMESTAMP NOT NULL
);Detta kommer nu garantera att alla tweets måste referera till ett ID som finns i tabellen users.
Det som kan vara komplicerat med referenser är den oklarhet som uppstår när man börjar ändra i tabellerna. Säg att vi vill radera en användare. Vad ska hända med alla tweets som den användaren har postat? Ska de försvinna? Ska de vara kvar av en användare som inte längre existerar? Ska de referera till en fantomanvändare? Vi måste alltså tänka på vad vi ska göra om det attribut vi refererar till raderas eller uppdateras.
Restriktioner på foreign keys
Restriktionen av en referens kan delas upp i två delar: när restriktionen ska testas, och vad restriktionen ska testa. Om man inte tilldelar attributet någon restriktion kommer det refererade attributet inte kunna ändras eller raderas. Så som tweets-tabellen ser ut nu kommer vi varken kunna radera eller uppdatera en användares ID. Vi kommer inte vilja ändra en användares ID (då det är en PRIMARY KEY) men vi skulle vilja ha möjligheten att kunna radera en användare (och därav användarens ID).
Det finns två tillfällen som en referens kan orsaka en restriktion att testas:
ON DELETE- Då det refererade attributet raderas.ON UPDATE- Då det refererade attributet uppdateras/ändras.
De vanligaste restriktioner är:
CASCADE- Tillåter uppdatering av det refererade attributet, eller raderar tuplen som refererar till attributet.SET NULL- Sätter tuplens attribut tillNULLom det som den refererar till ändras eller raderas.SET DEFAULT- Sätter tuplens attribut till ett förvalt värde om det som den refererar till ändras eller raderas.
Om vi sätter ON DELETE CASCADE som en restriktion så betyder det att om en användares id raderas så kommer även alla tweet som refererar till användares ID att raderas också. Om vi hade satt ON DELETE SET NULL hade alla användarens tweet fortfarande existerat, men posterID hade refererat till NULL.
CREATE TABLE tweets (
tweet_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
poster_id INTEGER REFERENCES users(user_id) ON DELETE CASCADE,
content TEXT NOT NULL CHECK(LENGTH(content) BETWEEN 4 AND 144),
time_posted TIMESTAMP NOT NULL
);Det finns en begränsning med foreign keys, nämligen att man bara kan referera till unika attribut, det vill säga attribut som har restriktionen UNIQUE eller PRIMARY KEY. I fallet med vår tweets-tabell skulle vi exempelvis inte kunna referera till attributet username.
PS: använd dig av DROP TABLE tweets; om du vill radera en tabellen tweets och skapa den på nytt. Mer om detta i nästa kapitel.
Many to many
Relationen mellan users och tweets kallar vi för one-to-many relation. Detta är för att en tweet kan vara kopplad till endast en användare, men en användare kan vara kopplad till flera tweets.
Nu vill vi skapa tabellen followers. Med followers vill vi kunna koppla en användare till flera följare, men också koppla flera följare till en användare. Denna relation blir då en many-to-many relation. För att kunna hantera denna situation måste vi använda oss av en tabell kallad associative table eller junction table.
I vårat exempel kommer varje par (användare, följare) att vara en primary key (composite key). Bägge attributen kommer även vara foreign keys till tabellen users. Varje tuple beskriver då en användare och vem den följer.
CREATE TABLE followers (
user_id INTEGER REFERENCES users(user_id) ON DELETE CASCADE,
follower_id INTEGER REFERENCES users(user_id) ON DELETE CASCADE,
PRIMARY KEY (user_id, follower_id)
);Nedan har vi ett exempel för det ska vara enklare att visualisera tabellen vi just skapade. För att underlätta använder vi namn istället för id.
| user | follower |
|---|---|
| transportwildcat | listenseagull |
| transportwildcat | wrapteal |
| wrapteal | transportwildcat |
Vi ser att transportwildcat har två följare (listenseagull och wrapteal) och följer wrapteal. Wrapteal följer transportwildcat och har även transportwildcat som följare. Listenseagull har inga följare men följer transportwildcat. Användaren entertainsnail finns inte med i tabellen, vilket betyder att det inte finns någon som följer entertainsnail och entertainsnail följer ingen.
Notera dessutom att vi har satt restriktionen PRIMARY KEY på en ny rad istället för direkt efter attributen. Detta är helt lagligt och nödvändigt när du vill skapa restriktioner på tabellen som berör flera attribut samtidigt. Detta kallas för en tabellrestriktion, istället för en kolumnrestriktion. Ett annat exempel på detta kan vara att se till att en användare inte följer sig själv:
CREATE TABLE followers (
user_id INTEGER REFERENCES users(user_id) ON DELETE CASCADE,
follower_id INTEGER REFERENCES users(user_id) ON DELETE CASCADE,
PRIMARY KEY (user_id, follower_id),
CONSTRAINT cant_follow_oneself CHECK (user_id != follower_id)
);Nu har vi skapat ett minimalt set av tabeller. I nästa kapitel är det dags att lägga in saker i dem!
Exercise
Vi har ett schema employees(employee_id, first_name, last_name, email). En restriktion som vi vill sätta på tabellen är att emailen ska sluta på
@job.com. Hur skulle den restriktionen se ut?
Solution
CREATE TABLE employees ( employee_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, first_name TEXT, last_name TEXT, email TEXT CONSTRAINT valid_email_check CHECK (email LIKE '%@job.com') );
Exercise
Två tabeller skapas enligt följande:
CREATE TABLE employees ( employee_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, first_name TEXT, last_name TEXT, email TEXT CONSTRAINT valid_email_check CHECK (email LIKE '%@job.com') ); CREATE TABLE salaries ( employee INTEGER REFERENCES employees(employee_id) PRIMARY KEY, salary INTEGER NOT NULL, bonus INTEGER, );
Kommer vi kunna sätta in en lön i tabellen
salariesför en anställd innan vi sätter in den anställda i tabelleremployees? Varför/varför inte?Kommer vi kunna ta bort en anställd från tabellen
employeesinnan vi tar bort lönen från tabellensalaries? Varför/varför inte?
Solution
Nej, för att attributet
employeei tabellen salaries är en foreign key som behöver referera till ett existerandeemployee_idi tabellen employees när det sätts in.Nej, för att då skulle det finnas en tuple i salaries som refererar till ett icke-existerande värde i tabellen employees. Det skulle däremot gå att göra det om vi hade definierat
ON DELETE CASCADE(som raderar tuplen) på våran foreign key. Vi skulle däremot inte kunna haON DELETE SET NULL, då attributetemployeeär dessutom enPRIMARY KEY, vilket inte kan varaNULL.
Exercise
I en databas finns två tabeller som representerar böcker och författare. En bok har ett id och en titel, medan en författare har ett id och ett namn.
Antag att en bok kan skrivas av en författare, men en författare kan skriva flera böcker (one-to-many). Hur löser vi detta med SQL-kod?
Antag nu istället att en bok kan vara skriven av flera författare, och att en författare kan skriva flera böcker (many-to-many). Hur löser vi detta med SQL-kod?
Solution
1.
Vi löser detta på samma sätt som vi gjorde med users och tweets. Eftersom en bok kan bara skrivas av en författare så kommer vi sätta in en foreign key i tabellen books som refererar till exakt en författare.
CREATE TABLE authors ( author_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, name TEXT NOT NULL ); CREATE TABLE books ( book_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, title TEXT NOT NULL, author INTEGER REFERENCES authors(author_id) );2.
För att skapa en many-to-many relation måste vi skapa en tredje tabell, så kallad associative table eller junction table, vars tuples består av foreign keys av de tabeller vi vill koppla ihop.
CREATE TABLE authors ( author_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, name TEXT NOT NULL ); CREATE TABLE books ( book_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, title TEXT NOT NULL, ); CREATE TABLE books_by_authors ( author INTEGER REFERENCES authors(author_id), book INTEGER REFERENCES books(book_id), PRIMARY KEY (author, books) );